
Data Driven Marketing: como armazenar os dados das suas iniciativas digitais?
A nossa série de webinars e artigos sobre Data Driven Marketing chega ao seu terceiro episódio para tratar de armazenamento de dados e como acessá-los nas suas estratégias. Nas duas primeiras gravações da série, nós mostramos um panorama geral do Marketing Orientado a Dados e ferramentas para tratar os dados depois de coletados.
Armazenamento de Dados
O conceito de armazenar dados consiste em agrupar arquivos e informações importantes coletadas em um ambiente seguro e que permita um acesso fácil aos dados. A prática se apoia em três etapas que são batizadas de ETL: Extract (extração), Transform (transformação) e Load (carregamento).
Extração
O primeiro passo dentro desse processo é extrair os dados dos diferentes sistemas presentes em uma empresa respeitando suas diferentes características e formatos. Informações de CRM’s, logaritmos, ERP’s etc são abrigadas em um stagging area, que funciona como um servidor temporário para os dados antes que eles passem para a etapa de transformação.
Transformação
É aqui que os dados brutos são manipulados para que ofereçam uma visão mais unificada e padronizada. Algumas fontes vão exigir maior manipulação dessas informações, enquanto outras podem se manter parecidas com sua forma bruta.
Carregamento
É nesse momento que os dados transformados são canalizados para serem armazenados em um lugar seguro. Cada projeto vai definir o melhor espaço para onde as informações devem ir, desde a migração dos dados de um sistema para outro, a disponibilidade para sistemas de BI, relatórios periódicos ou mesmo relatórios pontuais, enfim, a finalidade definirá a estratégia de armazenamento.
Eles podem ser transportados para um Data Mining ou um Data Warehouse, por exemplo. Diante dessas possibilidades, vamos conhecer um pouco mais sobre essas estratégias de armazenamento e quando elas devem ser utilizadas.
Estratégias de Armazenamento
Data Lake
Como o próprio nome diz, o Data Lake é como se fosse um grande lago cheios de dados. Ele é ideal para quem precisa abrigar uma quantidade grande de informações brutas, como arquivos, bancos de dados etc. Não é a melhor alternativa para quem precisa de dados direcionados, tratados e de fácil visualização. O Data Lake é para quem precisa de um repositório. Geralmente ele apresenta altos custos.
Data Warehouse
Voltado para dados mais estruturados e que já passaram por um processo de tratamento, o Data Warehouse é uma boa opção para quem não quer armazenar um volume muito grande de dados, mas precisa fazer buscas de maneiras simples, criando e organizando relatórios através de históricos que são depois usados pela empresa para ajudar a tomar decisões importantes com base nos fatos apresentados.
Data Mart
É uma subdivisão do Data Warehouse destinada àqueles que buscam relatórios muito específicos e de alta granularidade. Ideal para uma quantidade ainda menor de dados que devem estar ligados a apenas um departamento ou área a ser analisada. Uma proposta contrária ao do Data Lake.
Diantes dessas possibilidades, é preciso entender também as duas categorias de dados presentes nas estruras e modelagem de Data Warehouse: Os dados normalizados e os dados desnormalizados.
Os dados normalizados permitem um armazenamento consistente e acesso eficiente aos dados. Essa forma reduz a redundância de dados e as chances de inconsistência. Esse estilo de banco tem como foco inserir, alterar e deletar os dados.
Já os dados desnormalizados tem seu foco voltado para consulta. Permite alta performance na hora de recuperá-los, não garante integridade e a ordem aqui é duplicar os dados.
Modelo Estrela VS Modelo Floco de Neve
Outra técnica muito importante a ser levada em consideração no armazenamento de dados nos Data Warehouses é a Modelagem Dimensional. É uma maneira de modelar os dados levando em consideração como as informações se relacionam, se aprofundando em cada “eixo”. Vamos entender melhor explicando o Modelo Dimensional Estrela e o Modelo Dimensional Floco de Neve.
Modelo Estrela
Por ser focado em fatos e dimensões, este modelo permite uma fácil visualização do cenário analisado. No exemplo abaixo, o fato são os voos, centralizados no esquema. As dimensões são todas as variáveis que o rodeiam e são conectadas a ele nos chamados “joins”.
A vantagem desse modelo é a facilidade do entendimento dos relacionamentos, reduzindo o número de joins e tem baixa manutenção dados.
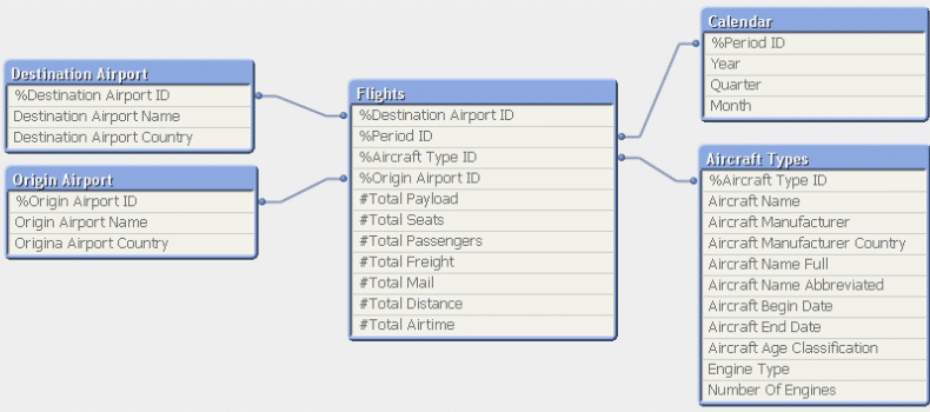
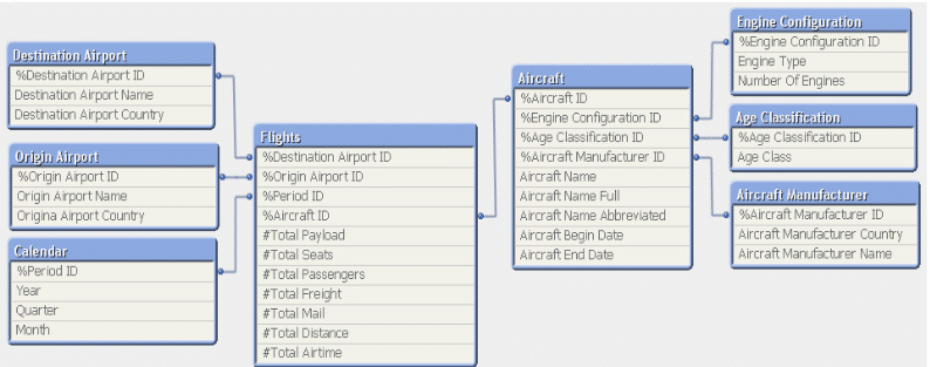
Modelo Floco de Neve
É considerado uma especialização do modelo estrela, pois é representado pela tabela fato centralizada e conectada a múltiplas dimensões, porém, permite fazer joins com tabelas individuais. Isso ajuda pois nem todas as tabelas precisam se ligar a todas as outras.
Algumas ferramentas de modelagem de banco de dados multidimensionais OLAP (Online Analytical Processing, – método de manipulação e análise de um grande volume de dados) são otimizadas para o modelo floco de neve, a normalização de atributos resulta em economia de armazenamento. Podemos citar a desvantagem do modelo é que a normalização dos atributos adicionam complexidade aos joins de consulta, e aumenta o gerenciamento e controle de atualização e inserção para garantir a integridade dos dados.
Ferramentas do Google Cloud Platform
Como já foi dito ao longo da série, o Google Cloud Platform é um grande aliado na gestão dos dados, inclusive no armazenamento. Podemos citar 3 principais produtos diante disso.
Cloud Storage: é onde ficam armazenados os arquivos, como o Data Lake, de maneira segura e estável
Cloud SQL: com a possibilidade de integração com o Google Marketing Platform, o SQL oferece facilidades no gerenciamento do banco de dados e com escalonabilidade
Big Query: na relação de custo benefício, o BigQuery é uma ótima ferramenta no mercado por armazenar dados com o total gerenciamento do Google e de forma personalizada. Os custos são baixos mesmo quando o volume de dados é grande. Além disso, permite análises avançadas e insights mais rápidos.


